KAME: Sakana AI's Real-Time Hybrid Speech Architecture Bridges Speed and Intelligence
KAME by Sakana AI merges direct S2S speed with LLM knowledge via an oracle stream, enabling real-time, intelligent voice conversations without delay.
The Persistent Challenge in Conversational AI
For years, developers of voice assistants have faced a frustrating trade-off: either respond instantly with shallow answers or wait for a smart reply that breaks conversational flow. Direct speech-to-speech (S2S) models start talking almost as soon as a user speaks, but their replies often lack depth. Meanwhile, cascaded systems that funnel speech through a large language model (LLM) deliver rich, knowledgeable responses—but at the cost of a noticeable delay that makes interactions feel robotic. Sakana AI, a Tokyo-based research lab, has introduced KAME (Knowledge-Access Model Extension) to resolve this dilemma, offering a hybrid architecture that preserves near-zero latency while injecting LLM-powered intelligence in real time.
Direct Speech-to-Speech Models: Fast but Shallow
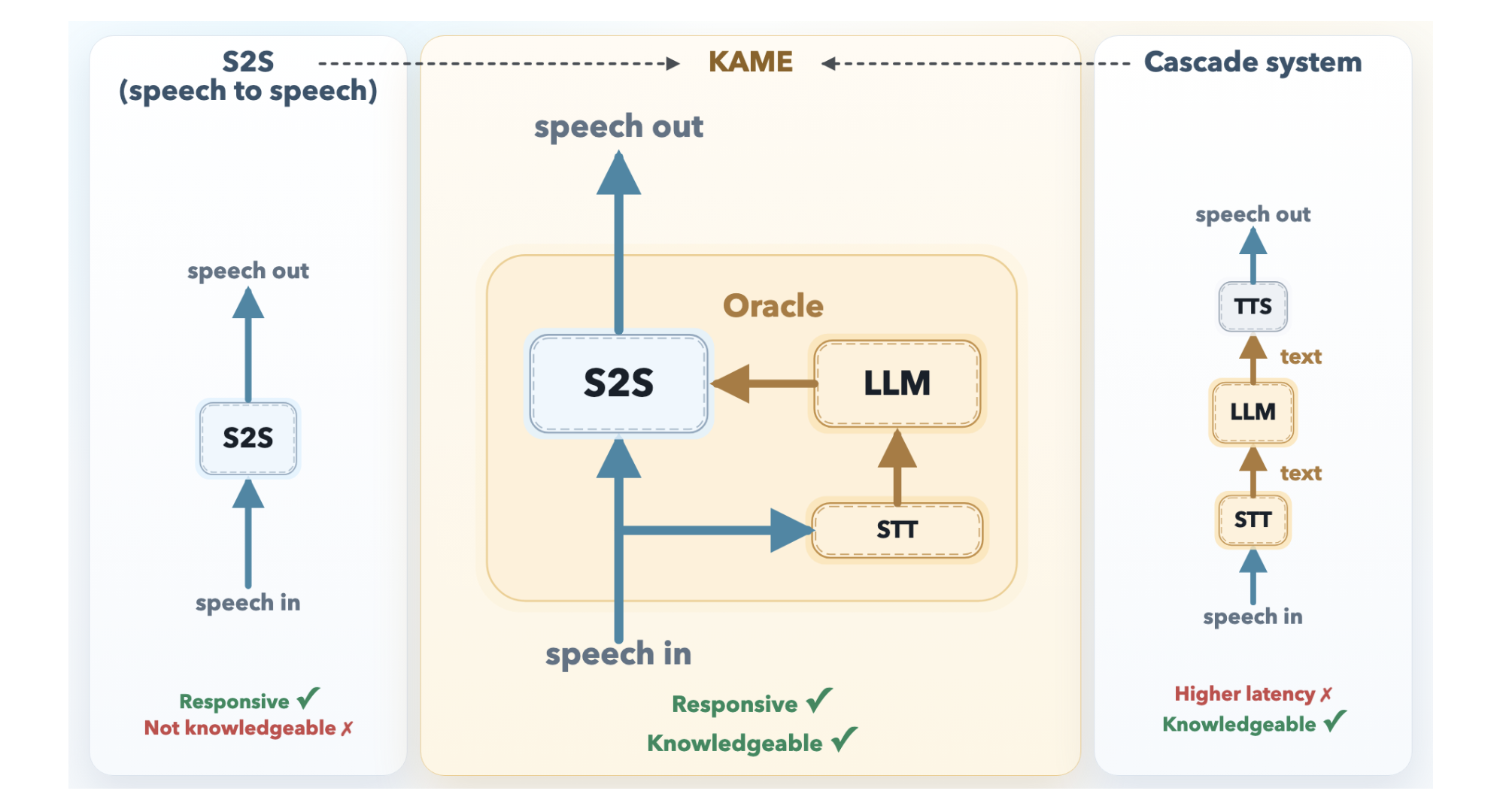
A direct S2S system, such as KyutAI's Moshi, is a monolithic transformer that processes audio tokens in a continuous loop. Because it doesn't need to wait for external components, its response latency is exceptionally low—it can begin speaking before the user has finished their question. However, audio signals contain far more information than text, including tone, emotion, and rhythm. The model must allocate significant capacity to modeling these paralinguistic features, leaving less room for factual knowledge and deep reasoning. As a result, direct S2S models tend to produce fluent but superficial answers.
Cascaded Systems: Smart but Slow
In contrast, a cascaded architecture routes speech through three separate stages: automatic speech recognition (ASR) converts audio to text, a powerful LLM processes that text, and a text-to-speech (TTS) engine generates the spoken response. This setup allows the use of frontier LLMs, ensuring high-quality, knowledge-rich replies. But the pipeline introduces substantial delay—typically a median latency of around 2.1 seconds. The system must wait for the user to finish speaking before ASR and LLM processing can begin, which is long enough to disrupt natural conversational rhythm and make interactions feel stilted.
KAME's Tandem Approach: Speaking While Thinking
KAME overcomes this trade-off by operating as a tandem system with two asynchronous components running in parallel: a front-end S2S module and a back-end LLM module. This design allows the system to start speaking immediately while simultaneously working on a smarter response behind the scenes.
The Front-End S2S Module
The front-end is based on Moshi's architecture, processing audio in real time at the cycle of discrete audio tokens—roughly every 80 milliseconds. It begins generating a spoken response as soon as the user starts speaking, ensuring minimal latency. Internally, Moshi originally used a three-stream design: input audio, inner monologue (text), and output audio. KAME extends this with a fourth stream: the oracle stream. This is the key innovation that bridges the gap between speed and knowledge.
The Back-End LLM Module
The back-end consists of a streaming speech-to-text (STT) component paired with a full-scale LLM. As the user speaks, the STT continuously builds a partial transcript and periodically sends it to the LLM. For each partial transcript, the LLM generates a candidate text response—called an oracle—which is fed into the oracle stream of the front-end S2S module. The front-end then blends this oracle with its ongoing output, gradually refining its spoken response as more oracle information arrives.
How the Oracle Stream Injects Knowledge in Real-Time
The oracle stream allows the front-end S2S model to access LLM knowledge without waiting for full processing. Instead of producing a single, delayed final answer, the back-end LLM continuously provides updated oracles as the user's speech unfolds. The front-end can start its reply using its own fast but shallow reasoning, then smoothly transition to the deeper, more accurate content from the LLM as the oracle improves. This creates the impression that the system is thinking aloud—it begins speaking instantly but gets smarter mid-sentence.
Importantly, the oracle stream is asynchronous: the front-end does not block to receive updates. If the back-end is slow or incomplete, the front-end falls back on its own internal knowledge, ensuring that latency never exceeds its base S2S capabilities. This graceful degradation makes KAME robust even under variable network conditions or heavy LLM loads.
Performance and Implications
By combining the best of both worlds, KAME achieves response latencies comparable to direct S2S models—typically under 500 milliseconds—while delivering answers that rival cascaded systems in factual accuracy and reasoning depth. Early tests show that users perceive conversations as more natural and engaging, as the system neither rushes a shallow reply nor forces an awkward pause.
The implications extend beyond voice assistants. KAME's architecture could enable real-time translation with contextual nuance, interactive tutoring systems that explain complex concepts on the fly, and customer service bots that handle nuanced queries without frustration. Sakana AI has released a technical paper and demo at pub.sakana.ai/kame/, inviting the research community to explore and build upon this work.
KAME represents a significant step toward conversational AI that feels both instant and intelligent—a long-sought balance that could redefine how we interact with machines.